Künstliche Intelligenz. Eine Begriffsklärung
Einleitung
Die Technik gibt es seit sehr langem. Der Mensch war schon immer abhängig von seiner Technik und verdankte ihr seinen kulturellen Aufstieg. Sie erleichterte das Überleben in der Natur, ermöglichte den Bau der Städte und die Entwicklung der Zivilisationen, half bei der Kriegsführung und der Erforschung und dem Bewohnen neuer Territorien. Mit der Zeit wurde die Technik immer komplexer: Angefangen mit einfachen Werkzeugen hat man gelernt, komplexere Maschinen zu bauen. Dies hatte wiederum eine enorme Wirkung auf die Kultur. Viele schwere Arbeiten konnten auf die Maschinen verlagert werden; die Bildung hat einen neuen Aufschwung bekommen; Wissenschaften hatten neue Mittel, um Experimente durchzuführen und immer weiter fortzusrchreiten. Schon sehr lange ist der Mensch von seiner Technik umgeben; Es ist nicht erst gestern passiert, dass er sich von ihr abhängig gemacht hat und seine Geschichte mit der der Technik verbunden hat. Was sich aber im Laufe der Zeit gewandelt hat, ist die Art der angesetzten Technik.
Es ist relativ neu, dass man angefangen hat, technischen Artefakten menschliche Eigenschaften zuzuschreiben. So spricht man heute von „intelligenten“ Maschinen. Es gibt intelligente Menschen, die gebildet, begabt sind. Die Maschinen, Computer werden programmiert, um einen bestimmten Zweck zu erfüllen, sie arbeiten nach einem vordefinierten Algorithmus. Bestenfalls kann so ein Algorithmus aktualisiert werden. Wäre es jedoch vielleicht möglich, ein Programm zu schreiben, das das menschliche Lernvermögen nachbildet und lernen kann? Es ist tatsächlich möglich und in diesem Fall spricht man von der künstlichen Intelligenz (Artificial Intelligence) und dem maschinellen Lernen (Machine Learning), von der Fähigkeit einer Maschine, selbst zu lernen, also den Algorithmus, nach dem sie arbeitet, weiter zu entwickeln und zu verändern. Das, was eine Maschine auf diese Weise gelernt hat, ist oft so komplex, dass man nicht mehr sagen kann, wie genau sie das gelernt hat und wie sie zu Ergebnissen kommt, die sie liefert. Ob es ausreichend ist, von der Intelligenz zu sprechen, im selben Sinne, wie man von der menschlichen Intelligenz spricht, ist eine schwierige Frage. Selbst die menschliche Intelligenz ist kein eindeutig definierter, ein vager Begriff, der viele subjektive Merkmale in sich trägt.
Dass wir die Programme entwickeln können, die sich selbst „weiterschreiben“, weiterentwickeln können, birgt viele Möglichkeiten und viele Gefahren in sich. Einerseits können die Maschinen dem Menschen nicht nur schwere körperliche Arbeit abnehmen, sondern auch einige geistige Tätigkeiten. Zum Beispiel das Übersetzen von Texten in andere Sprachen kann teilweise von Computern übernommen werden, die ihre „Sprachkenntnisse“ selbst immer mehr verbessern können. Andererseits, wenn man nicht mehr versteht, wie genau die von ihm konstruierte Maschine handelt, fühlt man sich bedroht. Es werden auch Stimmen laut, dass die nächste Stufe der Evolution nicht eine biologische, sondern eine technische Evolution sei und, dass der Mensch sehr bald vom Werk seiner Hände überholt werde.1
Das Ziel dieser Arbeit ist, auf die künstliche Intelligenz und neuronale Netze, nicht nur aus technischer, sondern auch philosophischer Sicht zu schauen. Wenn wir von der künstlichen Intelligenz sprechen, verwenden wir viele Begriffe wie Lernen, Lernerfolg, Intelligenz, deren Bedeutung aber nicht immer klar ist. Und ich finde, dass das, wie wir über die Maschinen sprechen, viel darüber sagt, wie sich unser eigenes Menschenbild im technischen Zeitalter verändert oder verändert hat.
Maschinelles Lernen
Maschinelles Lernen ist ein Zweig der künstlichen Intelligenz, in dem es darum geht, einem künstlichen System das Gewinnen von Wissen zu ermöglichen. Ein auf diese Weise lernendes System kann eine gestellte Aufgabe nicht nach einem vordefinierten Algorithmus lösen, sondern ist fähig, selbst zu lernen, wie die Aufgabe zu lösen ist.
Maschinelles Lernen ist sehr vielfältig und hat verschiedene Anwendungen. Es kann grob in zwei große Kategorien unterteilt werden: überwachtes und unüberwachtes Lernen.
Überwachtes Lernen (Supervised Learning)
Beim überwachten Lernen stehen dem Lernenden eine Menge von Eingaben und den dazugehörigen Ausgaben zur Verfügung. Das heißt es gibt eine Reihe von Ausgangsituationen und eine Reihe möglicher Antworten beziehungsweise Reaktionen auf jene Situationen, wobei zwischen den ersteren und den letzteren eine Abhängigkeit vorhanden ist. Das Ziel des Algorithmus ist jetzt diese Abhängigkeit zu entdecken, sie zu „erlernen“.
Supervised learning algorithms assume that some variable X is designated as the target for prediction, explanation, or inference, and that the values of X in the dataset constitute the „ground truth“ values for learning.2
Zum überwachten Lernen gehört auch das sogenannte bestärkende Lernen (Reinforcement Learning). Das ist das Lernen durch „Versuch und Irrtum“. Dem lernenden System steht hier keine Menge möglicher Ausgaben, sodass der Algorithmus aus vorhandenen Daten lernen könnte, dafür kann es mit seiner Umgebung interagieren und von dieser „belohnt“ oder „bestraft“ werden. Also der Algorithmus wird aus der Umgebung bewertet und anhand dieser Bewertung kann er lernen, wie er anhand einer Eingabe zu der richtigen Ausgabe gelangt.
„The learning algorithms used on reinforcement learning adjusts the internal neural parameters relying on any qualitative or quantitative information acquired through the interaction with the system (environment) being mapped, […]“3
Maschinelles und bestärkendes Lernen wird schon seit längerer Zeit bei Spam-Erkennung verwendet. Als Spam werden unerwünschte E-Mails, zum Beispiel Werbung, die man nicht bestellt hat, genannt. Es gibt auch einen Gegenbegriff zum Spam: Ham, also normale E-Mails, die man in seinem E-Mail-Postfach erwartet.
Wie ein Programm lernt, Spam von Ham zu unterscheiden, kann man damit vergleichen, wie es ein Mensch lernt. Sie bekommen unerwünschte Werbung per Post. Es ist ein Briefumschlag mit einer unpersönlichen Anrede und ein kleines Heft. Sie blättern es durch und sehen, dass sie daran nicht interessiert sind und schmeißen es weg. Wenn Sie ein ähnliches Heft nächstes Mal bekommen, blättern Sie vielleicht nochmal durch, um sicher zu sein, dass es nichts Wichtiges bzw. etwas, was Sie abonniert haben, ist. Wenn Sie einige Wochen später nochmal so ein Heft bekommen, reicht nur ein Blick. Vielleicht haben Sie den Namen desselben Unternehmens oder bekannte Produktabbildungen oder einen ähnlichen Werbetext gesehen — Sie schmeißen es, ohne genauer zu schauen, weg. Sie haben gelernt, dass derartige Hefte mit Werbung keine für Sie hilfreiche Information enthalten.
In vielen Mail-Programmen gibt es inzwischen die Funktion „Als Spam markieren“. Wenn eine E-Mail als Spam markiert wird, analysiert der Spam-Filter den Inhalt der E-Mail und merkt, wie viele Male jedes Wort in der Nachricht vorkommt. Dieselbe Analyse macht der Filter für die anderen Nachrichten, die nicht als Spam markiert wurden. Langsam sammelt sich eine Datenbank mit der Anzahl der Vorkommnisse verschiedener Wörter in Spam- und Ham-Nachrichten. Anhand dieser Daten kann dann der Filter erkennen, dass bestimmte Wörter nur in Spam-Mails vorkommen, aber nicht in Ham, und kann ohne die Einmischung des Menschen entscheiden, ob eine E-Mail unerwünscht ist oder nicht. So ein Verfahren ist natürlich nicht fehlerfrei. Es kommt sowohl dazu, dass Spam durch so einen Filter unerkannt durchdringen kann, als auch dazu, dass Ham im Spam-Ordner landet. Auf diversen Webseiten kann man lesen: „Wenn Sie keine E-Mail innerhalb von X Stunden erhalten haben, überprüfen Sie Ihren Spam-Ordner“. Wenn Ham als Spam eingestuft wird, spricht man vom False-Positive. Es gibt meistens wiederum die Funktion, um die Spam-Markierung von der E-Mail zu entfernen. Dadurch kann der Filter neu lernen und seine Datenbank aktualisieren beziehungsweise anpassen.
Wir haben gesehen, dass eine der Möglichkeiten, Spam zu erkennen, darauf basiert, den Spam-Filter mit der Umgebung, also mit dem Benutzer, kommunizieren zu lassen. Der Benutzer hat eine Möglichkeit dem Filter mitzuteilen, ob eine E-Mail Spam oder Ham ist, woraus der Filter lernen kann. Je länger so ein Filter eingesetzt wird und je mehr er auf diese Weise trainiert wird, desto geringer wird die Wahrscheinlichkeit des False-Positives.
Unüberwachtes Lernen (Unsupervised Learning)
Unsupervised learning algorithms do not single out any particular variables as a target or focus, and so aim to provide a general characterization of the full dataset.4
Beim unüberwachten Lernen wird keine bestimmte Ausgabe, kein bestimmter Wert bei der Ausgabe erstrebt, wie es bei dem überwachten Lernen der Fall ist. Vielmehr geht es darum, eine innere Struktur in den Daten zu entdecken.
Ein Standardbeispiel für unüberwachtes Lernen ist ein soziales Netzwerk. In großen sozialen Netzwerken kann man sein Interesse oder Desinteresse dadurch zeigen, dass man bestimmte Beitrage positiv markiert beziehungsweise blockiert. Ein gutes soziales Netzwerk würde, um seinen Nutzern genüge zu tun, die einem bestimmten Benutzer angezeigten Beiträge zensieren, und ihm nur diejenigen zeigen, die er wahrscheinlich mag und nicht diejenigen, die er blockieren würde. Aber das Netzwerk weiß nicht im Voraus, dass es Beiträge zu verschiedenen Themen gibt: Kunst, Politik, Sport und so weiter. Schließlich können immer neue Themen auftauchen. Das Netzwerk lernt selbst die Beiträge und Benutzer zu klassifizieren. Das Lernen geht über die Erforschung der Vorlieben einer bestimmten Person hinaus. Nehmen wir an in Profilen zweier Personen unter „Interessen“ steht, dass sie gern Tennis spielen und beide lesen gerne Nachrichten eines Sportvereins, der eine eigene Seite im sozialen Netzwerk hat. Wenn eine dritte Person jetzt angibt, dass sie gern Tennis spielt, hat das soziale Netzwerk den Grund anzunehmen, dass dieser Person auch die Nachrichten des Sportvereins gefallen werden. Das heißt das Netzwerk lernt aufgrund komplexer Zusammenhänge, dass es bestimmte Gruppen, Themen- und Interessenbereiche gibt. Es gibt hier keine richtige Antwort, man überwacht nicht alle registrierten Benutzer und korrigiert das Netzwerk nicht: Nein, dieser Mensch gehört dieser Gruppe nicht. Und wenn ich einen Beitrag blockiere und markierte, bedeutet es nicht unbedingt, dass ich eine Bewertung abgebe, wie gut das Netzwerk gelernt hat. Es kann schließlich sein, dass ich heute keine Lust auf meinen Sportverein habe, sonst aber gerne lese, was er schreibt.
Die Unterteilung in Gruppen, Klassifizierung ist in der Wirklichkeit sehr komplex und unterzieht sich oft der Möglichkeit, sich auf irgendeine Weise kontrollieren oder bewerten zu lassen. Unüberwachtes Lernen kann hier Abhilfe schaffen.
Neuronale Netze
In diesem Abschnitt handelt es sich um eine mögliche Realisierung des maschinellen Lernens und zwar anhand der neuronalen Netze.
Biologisches Vorbild
Ein „neuronales Netz“, wie der Name raten lässt, ist ein Netz das aus Neuronen beziehungsweise Nervenzellen besteht. Das Neuron ist kein technischer Begriff, er stammt aus der Biologie: „[…] die Nervenzelle — das Neuron — [ist] der Grundbaustein und die elementare Signaleinheit des Gehirns […]“5 Neuronale Netze haben nicht nur den Begriff des Neurons aus der Gehirnforschung übernommen, sondern auch einige weitere, und überhaupt haben sie menschliches Gehirn zu ihrem Vorbild.
Die Nervenzelle besteht aus drei Komponenten: einem Zellkörper mit zwei Arten von Fortsätzen, Axone und Dendriten.6 Diese Fortsätze der Nervenzelle dienen der Signal- beziehungsweise der Informationsübertragung:
Mit den Dendriten empfängt das Neuron Signale von anderen Nervenzellen, und mit dem Axon sendet es Informationen an andere Zellen. […] Die Axonendigungen eines Neurons kommunizieren mit den Dendritten eines anderen Neurons nur an speziellen Stellen, die von Sherrington später Synapsen genannt wurden (von griechisch sýnapsis — „Verbindung“).7
Synapsen sind ein weiterer Begriff, der für maschinelles Lernen wichtig ist. Sie verbinden die Neuronen miteinander und kodieren die bisher gelernten Informationen. In künstlichen sowie in biologischen neuronalen Netzen sind nicht alle Neuronen miteinander verbunden. Im Falle der biologischen neuronalen Netze sind „Nervenzellen innerhalb bestimmter Bahnen verknüpft […], die er [Santiago Ramón y Cajal] neuronale Schaltkreise nannte. Signale bewegen sich darin in vorhersagbaren Mustern.“8 Auch im Gehirn sind die Synapsen für die Informationsspeicherung und Lernerfahrung verantwortlich, da das Lernen die synaptische Stärke und dadurch die Kommunikation zwischen Neuronen verändern kann.9
Einschichtiges feedforward-Netz
In diesem Abschnitt soll die Funktionsweise eines neuronalen Netzes an einem Beispiel erklärt werden. Nehmen wir an, wir wollen den Zusammenhang zwischen der Anzahl der Stunden, die man mit dem Lernen und dem Schlafen am Tag vor einer Klausur verbracht hat, und dem Ergebnis der Klausur, gemessen in Prozent, herausfinden.
Zu unseren Eingabedaten zählen:
Stunden geschlafen.
Stunden gelernt.
Basierend auf diesen Daten wollen wir vorhersagen, wie das Ergebnis der Klausur ausfällt. Da wir am Anfang nicht blind raten wollen, nehmen wir auch an, dass wir eine Testperson zur Verfügung haben, die uns für die Untersuchung notwendige Parameter und das Endresultat ihrer Klausur mitteilt.
| (gelernt; geschlafen) | Ergebnis |
|---|---|
| (3 Std; 5 Std) | 70% |
Diese Daten wollen wir verwenden, um unser neuronales Netz zu „trainieren“, d.h. es muss anhand dieser Daten Vorhersagen über einen wahrscheinlichen Verlauf künftiger Klausuren machen können.
Bei unseren Berechnungen wollen wir nicht mit verschiedenen Maßeinheiten arbeiten. Zum Beispiel in unseren Daten haben wir die Eingabe in Stunden und die Ausgabe in Prozent, es ist allerdings nicht möglich Stunden in Prozente zu übersetzen oder umgekehrt. Unser Netz ist aber auch an Maßeinheiten oder an der Art unserer Daten nicht interessiert, es muss schließlich mögliche Zusammenhänge zwischen den Eingabe- und Ausgabewerten finden, unabhängig davon, ob es nun Stunden, Prozente, Kilogramme oder Meter sind.
Außerdem soll die Ausgabe die folgende Bedingung erfüllen soll:
Um bessere Ergebnisse zu bekommen, werden wir hauptsächlich mit reellen Zahlen von 0 bis 1 rechnen. Um das zu erreichen werden die Stunden und die Prozentzahl durch 100 geteilt. Nach diesen Umwandlungen erhalten wir die folgende Tabelle:
Normalisiert
| (gelernt; geschlafen) | erwartetes Ergebnis |
|---|---|
| (0,03; 0,05) | 0,7 |
Gewichtung
Unser neuronales Netz wird insgesamt aus drei Schichten bestehen:
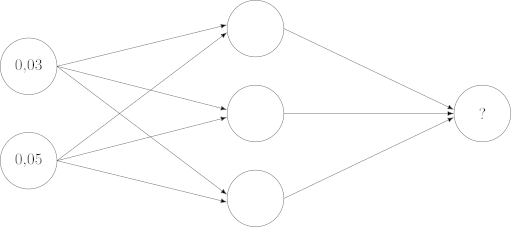
Jede dieser Schichten hat wiederum eins oder mehrere Neuronen. Jedes dieser Neuronen kann Daten speichern (in unserem Fall — eine Zahl). Die Neuronen sind untereinander mit Synapsen verbunden. Eine Synapse kann wiederum Informationen speichern, i.e. sie werden auch mit einer Zahl versehen.
Die erste Schicht (Abbildung , links) ist die Eingabeschicht, sie enthält die Eingabedaten. Als Eingabe haben wir zwei Werte pro Testlauf: die Anzahl der Stunden, die die Testperson gelernt und geschlafen hat. Diese zwei Werte sind unseren Eingaben, weil es die Daten sind, auf deren Basis wir eine Ausgabe erwarten, eine Vorhersage machen wollen. Die Ausgabeschicht ist die letzte Schicht (Abbildung , rechts), sie hat nur ein Neuron, das Ergebnis der Klausur, das wir erwarten. Schließlich in der Mitte ist die verdeckte Schicht. Sie ist verdeckt, weil sie für den Endbenutzer nicht sichtbar ist, der Endbenutzer gibt schließlich eine Eingabe und bekommt am Ende eine Ausgabe, dazwischen werden, basierend auf dem, was das neuronale Netz vorher gelernt hat, nur eine Reihe von Berechnungen durchgeführt.10
Nun hat unser Netz noch nichts gelernt, wir wollen das erstmal nur trainieren. Für den ersten Lauf müssen wir deswegen eine Reihe von Parametern zufällig wählen.
Erstens brauchen wir die sogenannten Gewichte. Gewichte sind Werte, die den Synapsen zugeordnet werden. Sie bestimmen, welchen Einfluss ein Eingabewert auf das Endergebnis hat. Die Gewichtung repräsentiert, was das Netz bisher gelernt hat.
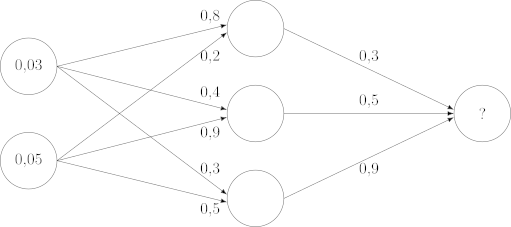
In unserem Fall haben wir insgesamt 9 Synapsen, sodass jedes Neuron der Eingabeschicht mit allen Neuronen der verdeckten Schicht, und jedes Neuron der verdeckte Schicht mit dem Neuron der Ausgabeschicht verbunden werden kann. Ich versehe diese Synapsen mit den folgenden Werten (von oben nach unten und von links nach rechts): 0.8, 0.4, 0.3, 0.2, 0.9, 0.5, 0.3, 0.5, 0.9. Es gibt erstmal keinen Grund, diese Werte und nicht andere auszuwählen. Sie sind zufällig gefällt und die einzige Bedingung, die sie erfüllen müssen, ist, dass jeder dieser Werte im Intervall liegen soll.
Schließlich müssen wir die Neuronen der Eingabeschicht mit unseren Ausgangsdaten füllen. Unsere Ausgangssituation graphisch dargestellt ist dann die folgende:
Vorwärtspropagation
Im nächsten Schritt wird die verdeckte Schicht gefüllt. Da wir zwei Neuronen in der Eingabeschicht haben und jedes davon ist den Neuronen der verdeckten Schicht verbunden ist, führen jeweils zwei Synapsen von der Eingabeschicht zu einem der Neuronen der verdeckten Schicht. Wir multiplizieren den Wert des Neurones der Eingabeschicht mit den Gewichten der daraus ausgehenden Synapsen, addieren die Ergebnisse zusammen und schreiben das Endergebnis in das entsprechende Neuron der mittleren Schicht. Die Werte jedes der Neuronen der verdeckten Schicht werden also wie folgt berechnet:
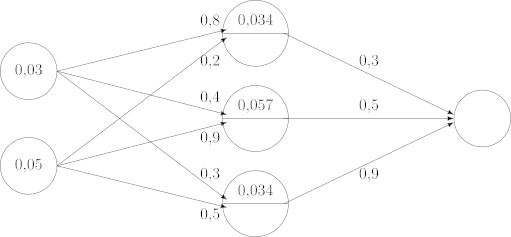
Aktivierungsfunktion
Da die Eingabe (die Stunden) nicht im Intervall liegt, verwenden wir eine logistische Aktivierungsfunktion, deren Wertebereich ist: „The output result produced by the logistic function will always assume real values between zero and one.“11
So bekommen wir nach den anschließenden Berechnungen mit einer hohen Wahrscheinlichkeit eine Zahl zwischen 0 und 1, die anschließlich mit 100 multipliziert werden kann, um so auf die Prozente zu kommen.
Wir wenden zunächst die Aktivierungsfunktion auf jeden der vorher berechneten Werte an und schreiben das Ergebnis ebenfalls in die verdeckte Schicht.
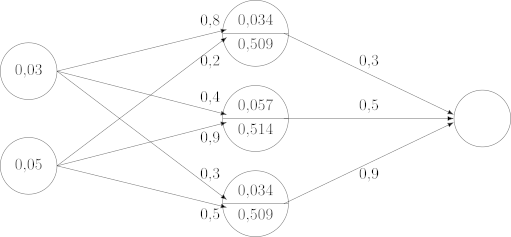
Es bleibt jetzt nur noch dieselbe Berechnung durchzuführen wie mit der Eingabeschicht: Jeder der Werte der verdeckten Schicht wird mit dem entsprechenden Gewicht multipliziert und alle Ergebnisse werden anschließend summiert.
Hier ist das komplett ausgefüllte neuronale Netz für unsere Testperson:
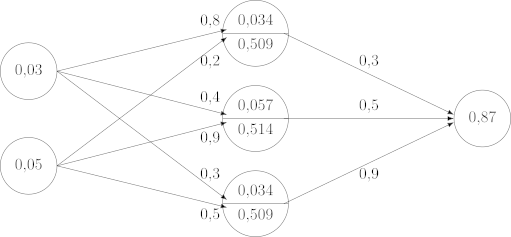
Fehlerrückführung
Man muss einsehen, dass das Resultat, zu dem wir am Ende kamen, absolut zufällig ist. In fast jeder Berechnung wurden Gewichte verwendet, die am Anfang zufällig ausgewählt wurden. Das heißt, wenn ich mich für andere Gewichtung entschieden hätte, käme auch etwas anderes dabei heraus. Und das ist jetzt die Aufgabe, die bevorsteht: die Gewichtung so anzupassen, dass sie zu einem genaueren Ergebnis führt. Dieser Schritt heißt Fehlerrückführung. Man versucht hier den Fehler geringer zu machen. In unserem Fall ist das Ergebnis, das wir erwartet haben, 0.7. Statdessen haben 0.87, was um 0.17 größer als das erwartete Ergebnis. Wenn wir diese Distanz zwischen dem aktuellen und dem erwarteten Ergebnis geringer machen, trainieren wir das neuronale Netz.
Es gibt mehrere Methoden, die Fehlerrückführung durchzuführen. Die einfachste (und die schlechteste für die Praxis, weil sie für ein größeres Netz zu viel Zeit in Anspruch nehmen würde) wäre, einige der Gewichte zu ändern (man kann dafür wiederum andere zufällige Zahlen von 0 bis 1 verwenden), und alles dann nochmal mit diesen neuen Gewichten berechnet. Wenn man zu einem besseren Ergebnis kommt, kann man versuchen, die Gewichtung weiter anzupassen, bis das Resultat zufriedenstellend ist. Wenn das Ergebnis noch schlechter wird, versucht man dasselbe mit anderen Gewichten.
Das heißt, die Vorwärtspropagation und Fehlerrückführung werden mehrmals wiederholt, bis das Endresultat ausreichend genau ist. Schließlich ist eine Testperson für das Trainieren des neuronalen Netzes nicht ausreichend. Wenn wir weitere Daten erhalten, können wir sie genauso einsetzen, und den Endwert mit denselben Gewichten für diese neuen Daten berechnen. Dann können wir versuchen, die Gewichtung so anzupassen, dass für die beiden Fälle ein genaueres Ergebnis herauskommt. Dann ziehen wir noch eine dritte Testperson hinzu und so weiter… Irgendwann haben wir die Gewichtung so gewählt, dass wir damit rechnen können, dass wenn wir dem Netz neue Daten übergeben, wir eine gute Einschätzung für die Endnote bekommen. Es ist kaum möglich mit dem oben aufgeführten Netz. Neuronale Netze sind in der Praxis viel komplexer und haben mehrere verdeckte Schichten, was genauere Anpassung der Gewichte ermöglicht.
Lernerfolg. Turing-Test
Im Zusammenhang mit dem maschinellen Lernen sprechen wir vom Lernerfolg. Allerdings wurde es noch nicht geklärt, was Erfolg in diesem Fall bedeutet.
Um einen gewöhnlichen Einwand gegen den Erfolg der künstlichen Intelligenz zu erläutern, konstruieren wir ein futuristisches Beispiel, das in einer oder der anderen Form zum Thema vieler Filme der letzten Jahre geworden ist. Sagen wir, die Menschen haben einen Supercomputer entwickelt, dessen künstliche Intelligenz dermaßen fortgeschritten ist, dass er selbst weitere Maschinen entwerfen und produzieren kann. So beginnt eine neue Ära, in der die Maschinen sich selbt ohne die Einmischung des Menschen entwickeln. Schlussendlich wird der Mensch zu einer überholten, schwachen Spezies, deren Existenz nicht mehr förderlich für den weiteren technischen Fortschritt ist, sodass der mächtige Supercomputer sich dazu entscheidet, die menschliche Art auszulöschen. Nun hatte der Supercomputer, der eine solche Macht erlangt hat, alles über die Wissenschaft und Technik gelernt, was der Mensch je hätte lernen können, und diese Kenntnisse noch weiter gebracht hat. Man könnte sich aber fragen, ob der Erfolg des Lernens an der Anzahl der Erkenntnisse gemessen werden kann. In dem aufgeführten Beispiel hat sich die Technik, die der Mensch sich zuhilfe schuf, hatte gegen den Menschen gewendet und so gegen das moralische Prinzip, nach dem das menschliche Leben einen Wert an sich hat, verstoßen.
Wenn wir also vom Erfolg sprechen, beziehen wir den Erfolg nicht nur auf die eigentliche Tätigkeit (das Erwerben von Erkenntnissen), sondern auch auf das Endresultat — wie die erworbenen Erkenntnisse angewandt werden. Bei der Bewertung ihrer Anwendung braucht man wiederum eine Ethik, die es ermöglicht, zu beurteilen, ob die Anwendung richtig oder falsch, gut oder böse ist. Man sieht sofort, wie schnell das Problem des Erfolgs sehr komplex und unübersichtlich wird. Ich werde deswegen dafür argumentieren, dass der Erfolg des Lernens nur in dem Sinne des unmittelbaren Erfolgs ohne die Einbeziehung der Konsequenzen verstanden werden muss. Desweiteren werde ich versuchen den Erfolg anhand des Turing-Tests etwas genauer zu bestimmen.
Alan Turing stand vor einem ähnlichen Problem, als er das, was wir heute Turing-Test nennen, vorgeschlagen hat. Das Lernen, die Suche nach Gesetzmäßigkeiten und die Anwendung des Gelernten und Erforschten sind wichtige Aspekte menschlicher Denktätigkeit. Wenn wir davon sprechen, dass die Computer selbstständig lernen, stellt sich die Frage, ob sie dann auch denken kennen? Um zu sagen, ob die Computer denken können, muss man dann definieren, was das Denken eigentlich ist und dann schauen, ob diese Definition auf die Computersysteme angewandt werden kann.
Nun ist es aber alles andere als trivial, eine Definition für das Denken zu finden. Das eigentliche Problem besteht aber nicht darin, dass eine solche Definition eine schwierige Aufgabe ist, sondern darin, dass die Angabe einer Definition des Denkens sich sowohl dem Interessenbereich der Technik als auch dem Interessenbereich der Wissenschaft entzieht. Wir verbinden das Denken mit den Gehirnaktivitäten. Aber spielt es für einen Gehirnforscher in seiner wissenschaftlichen Forschung eine Rolle, was das Denken ist? Er kann durchaus eine private Überzeugung haben, dass das, was wir unter dem Denken verstehen, nichts weiter als die Gehirnaktivität ist, oder, dass das, was wir im Gehirn beobachten, nur auf eine bestimmte Weise unser Denken repräsentiert. Aber ob er sich für die erste Möglichkeit, oder für die zweite, oder für eine dritte entscheidet, ist für seine eigentliche wissenschaftliche Forschung von wenig Bedeutung. Auch umgekehrt: Wenn man eines Tages weiß, dass man jede geistige Aktivität auf Gehirnaktivitäten zurückführen kann, bedeutet es, dass ich mich ab dann für einen vollständig von den physikalischen Gesetzen bestimmten Bio-Roboter halte, der keinen eigenen Willen hat?
Es ist ganz natürlich den Gegenständen menschliche Eigenschaften und Aktivitäten zuzurschreiben: „Der Computer will nicht funktionieren“. Natürlich kann es bei einem kaputten Rechner keine Rede vom Willen sein. Das ist bloß eine Redewendung. Aber wenn die Computer viel leistungsfähiger werden, passiert die Zuschreibung viel bewusster, wir fangen an, von ihrer Intelligenz, ihrem Denken oder dem Erfolg ihrer Aktivitäten zu sprechen. Diese Begriffe sind aber in der Sprache sehr oft ambivalent und werden intuitiv verwendet. Deswegen ist es auch problematisch, sie auf andere Gegenstände zu übertragen.
Um das höchstproblematische Reden vom Denken im Fall der Computer zu vermeiden, hat Alan Turing „The Imitation Game“12 vorgeschlagen. Dieses Imitationsspiel wird von drei Personen gespielt: einem Mann (A), einer Frau (B) und einem Fragesteller (C), dessen Geschlecht für das Spiel irrelevant ist. Der Fragesteller kennt die beiden anderen Personen A und B nicht und befindet sich in einem anderen Raum. Das Ziel des Spiels für den Fragesteller besteht darin, richtig zu erraten, wer von A und B ein Mann und wer eine Frau ist. Dabei kann der Fragesteller den übrigen Spielteilnehmern Fragen stellen und Antworten auf seine Fragen bekommen. Die Teilnehmer kommunizieren miteinander so, dass der Befragende und die Befragten einander weder sehen noch hören können, zum Beispiel sie könnten einander Texte über das Internet versenden. A und B sind nicht verpflichtet, ehrliche Antworten auf die Fragen zu geben. Die Aufgabe von A ist, dem Befragenden zu helfen, B soll ihn im Gegenteil in die Irre führen.13
We now ask the question, „What will happen when a machine takes the part of A in this game?“ Will the interrogator decide wrongly as often when the game is played like this as he does when the game is played between a man and a woman? These questions replace our original, „Can machines think?“14
Das heißt, die Maschine soll die Rolle eines Spielers — entweder A oder B — übernehmen. Es gibt keine Frau, keinen Mann und Fragesteller mehr, sondern einen Menschen, eine Maschine und den Fragesteller (menschlich). Wenn es für den Fragesteller genauso schwierig ist, ohne einen direkten Kontakt eine Maschine von einem Menschen zu unterscheiden, wie eine Frau von einem Mann, dann hat die Maschine den Turing-Test bestanden.
Im Grunde, um den Erfolg des Lernens eines Computersystems zu bewerten, wird hier eine funktionale Beschreibung verwendet. Anstatt nach der Washeit der Dinge zu fragen: Was ist Denken? Was ist Erfolg? Können diese Begriffe auf ein Computersystem angewandt werden?, fragt man, ob und wie gut das System eine bestimmte Funktion ausführen, einen Test bestehen kann. Der Turing-Test scheint mir auch die beste Methode zu sein, um den Erfolg des Lernes eines Computersystems zu bewerten. Vor allem, weil so ein funktionaler Test einen Aufschluss darüber gibt, welche Stufe in der Entwicklung der künstlichen Intelligenz man bereits erreicht hat, und was noch verbessert werden muss, um den Lernerfolg zu vergrößern. Er gibt auch eine Skala an, von der abgelesen werden kann, ob ein Algorithmus bessere Ergebnisse liefert als ein anderer. Dies ermöglicht den technischen Fortschritt und die Verbesserung der Algorithmen. Diese Skala gibt es aber nicht oder sie ist sehr verschwommen, wenn der Lernerfolg eine ethische Perspektive haben soll.
Was ich hiermit nicht sagen will, ist, dass die Ethik für die Entwicklung der künstlichen Intelligenz unwichtig ist. Es macht nur wenig Sinn sie in die Definition des Lernerfolgs eines künstlichen Systems einzubeziehen. Um so ein System weiter zu entwickeln, braucht man eine technische Definition des Erfolgs, die ermöglicht, die Schwächen dieses Systems aufzuzeigen, an denen noch gearbeitet werden soll. Eine voreilige Einbeziehung einer ethischen Bewertung würde den Fortschritt im Bereich der künstlichen Intelligenz unnötig verkomplizieren und verlangsamen. Eine ethische Bewertung der künstlichen Intelligenz als solchen und dessen, wie sie eingesetzt wird, ist im Gegenteil nützlich und nötig, um die Möglichkeit einer bösartigen Anwendung deren zu verringern.
Ich meine auch nicht, dass eine ethische Auseinandersetzung der technischen Entwicklung zeitlich folgen soll. Es kann zu spät sein, sich mit etwas auseinanderzusetzen, was schon da ist. Vielmehr sollen die Bereiche des Technischen und Ethischen voneinander getrennt sein. Wenn ein Informatiker oder ein Mathematiker an einem neuen Algorithmus für maschinelles Lernen arbeitet, ist er wahrscheinlich gar nicht daran interessiert, ein künstliches System zu erschaffen, das ihm ermöglicht, die Welt zu beherrschen, womöglich ist er nur an seinem Fach interessiert und will sehen, wie weit man die künstliche Intelligenz bringen kann. Natürlich soll man sich Gedanken darüber machen, was passiert, wenn man den neuen Algorithmus oder die neue Technologie auf den Markt bringt, das darf aber nicht der eigentlichen Forschung im Wege stehen.
Dritt- und Erstperson-Perspektive
Kommen wir auf die Frage „Können die Maschinen denken?“ zurück. Was ist an dieser Frage so problematisch, sodass Alan Turing sie umzugehen suchte, außer dass der Begriff „Denken“ schwierig zu definieren ist. Oder warum ist er schwierig zu definieren? Das Denken für den Menschen ist ein Erlebnis, das heißt ich erlebe mich selbst als ein denkendes Wesen. Ich gehe davon aus, dass auch die anderen Menschen sich als denkende Wesen erleben, obwohl ich nicht mit Sicherheit sagen kann, wie sich das Denken eines anderen Menschen für ihn anfühlt, was und wie er denkt. Man denke nur an die Diskussionen, ob Tiere Freude oder Leiden empfinden können, ob sie denken können. Es ist relativ naheliegend, dass andere Menschen denken können, aber es ist nicht klar, ob man das von den anderen Lebewesen behaupten kann. Desto unklarer ist es, wenn man von etwas spricht, was überhaupt kein Lebewesen ist.
Anstatt der Maschine einen Geist und eine Art Innerlichkeit zuzuschreiben, entwickelt sich aber die Tendenz, den Menschen mechanisch zu verstehen. Wenn Sören Kierkegaard sagt: „Der Mensch ist Geist“15, so heute ist der Mensch immer öfter sein Gehirn: „In Germany, leading neuroscientists like Wolf Singer and Gerhard Roth are omnipresent in TV and press. They speak of the brain as if they were talking about a person.“16 Kierkegaards Mensch und sein Geist waren nicht bloß eine immaterielle Substanz, sondern vielmehr eine Synthese „aus Unendlichkeit und Endlichkeit, aus dem Zeitlichen und dem Ewigen, aus Freiheit und Notwendigkeit, […]“17 Ob die Beschreibung des Menschen als Gehirn genauer zutrifft, ist fraglich. Yvonne Förster in ihrem Artikel „Effects of the Neuro-Turn: The Neural Network as a Paradigm for Human Self-Understanding“ macht darauf aufmerksam, dass obwohl bei der Erforschung des Gehirns nur die Drittperson-Perspektive in die Betrachtung einbezogen wird, eine Verschiebung der Terminologie von der Philosophie zu den Neurowissenschaften stattfindet:
While phylosophy works with concepts, experience, reflection, and linguistic description, neuroscience, on the other hand, uses these philosophical terms within a third-person framework of observation, imaging techniques, and measurements.18
Eine Reihe von Begriffen, wie der freie Wille oder das Bewusstsein, für die die Innenperspektive unentbehrlich ist, werden aus der Drittperson-Perspektive beurteilt und beschrieben. Doris Nauer spricht auch davon, dass bei der Erforschung geistiger Funktionen „NaturwissenschaftlerInnen zunehmend die Interpretationsgrenzen rein naturwissenschaftlicher Forschung überschreiten“.19 Außerdem merkt Förster an, dass die Neurowissenschaften keinen direkten Zugang auch zum Gehirn oder den Neuronen selbst haben, vielmehr arbeiten sie mit Modellen:
The neural gains its visibility only via technology. The process of making the neural visible is not a simple representation of something otherwise hidden. Rather it is a production of images by means imaging techniques. What we get to see is not the inside of our skull, not copies of our neurons, but reconstructions modeled according to a certain set of rules of computation. The neural net as we know it from neuroscientific imagery is not a photograph of brain parts. It is deeply technological mediated.20
Das Selbstverständnis des Menschen und das Verständnis der Maschine und der künstlichen Intelligenz sind voneinander abhängig. Wenn wir die Maschinen konstruieren, die selbst lernen und vielleicht denken können, und so den Menschen nachahmen, lernen wir auch etwas über die menschlichen Denkprozesse und dem Zusammenhang zwischen dem Bewusstsein und dem Gehirn. Andererseits um zu entscheiden, ob die Maschinen denken oder ein geistiges Leben haben können, ist unser Menschenbild wichtig, weil es von ihm abhängt, ob sich das, was wir unter dem Menschen verstehen, auf die Maschine übertragen lässt.
Zum Begriff der Intelligenz
Eine der Fragen, die sich noch stellen, ob wir im Falle der künstlichen Intelligenz überhaupt von der Intelligenz sprechen kann, wie wir von der menschlichen sprechen. Ich möchte von vornherein sagen, dass diese Frage nicht eindeutig zu beantworten ist. Von einem Menschen zu sagen, er sei intelligent, ist nicht dasselbe, wie zu sagen: „Zwei ist eine gerade Zahl“.
Erstens, je nachdem wer das Wort „intelligent“ sagt, kann man darunter unterschiedliche Eigenschaften meinen. Für einen mag intelligent derjenige sein, der über viele Fachkentnisse in einem bestimmten Bereich verfügt. Für einen anderen ist es der, der allgemein gebildet ist und nicht nur in bestimmten Bereichen. Für den dritten spielen die erworbenen Kenntnisse überhaupt eine geringere Rolle, viel wichtiger, um intelligent zu sein, sei es, schlau zu sein, schnell die Lösungen für die auftretenden Probleme zu finden.
Zweitens hängt die Antwort auf die Frage, ob man so eine Eigenschaft wie „Intelligenz“ auf eine Maschine übertragen kann, sehr stark von anthropologischen Ansichten der jeweiligen Person. Ist der Mensch selbst wahrscheinlich nichts weiter als eine Art von der Natur erschaffener Roboter? In diesem Fall kann wohl auch eine vom Menschen konstruierte Maschine Intelligenz haben. Wenn der Mensch dagegen ein geistiges Wesen ist, das nicht vollständig durch physikalische Gesetze determeniert ist, dann ist es qualitativ etwas anderes als eine Maschine und man könnte argumentieren, dass deswegen bestimmte Eigenschaften wie Intelligenz nur dem Menschen zugeschrieben werden können.
Der Stand der Entwicklung rechtfertigt nicht immer die Anwendung des Begriffes „Intelligenz“ im Bezug auf die Maschinen. Bereits heutige Computer sind in bestimmten Bereichen intelligenter als die Menschen. Zum Beispiel kann jeder der heutigen Prozessoren (oder CPU, Central Processing Unit) einfache Berechnungen, wie Multiplizieren, Dividieren, Addieren oder Substrahieren, vielfach schneller durchführen als ein Mensch. Und diese Fähigkeit besitzten bereits die Computer der neunziger Jahre des vergangenen Jahrhunderts, als die künstliche Intelligenz noch nicht so verbreitet war. Schnelles Rechnen kann auch ein Merkmal der Intelligenz sein. Und doch spricht man von der künstlichen Intelligenz meistens in Bezug auf maschinelles Lernen. Dies zeigt, dass wenn man von intelligenten Maschinen spricht, meint man eine bestimmte Art von der Intelligenz, und zwar meint man die Maschinen, die das Können besitzen, nicht nur die einprogrammierten „Kenntnisse“ anzuwenden, sondern auch neue Erkenntnisse selbstständig zu gewinnen. Das heißt Intelligenz knüpft hier an die schöpferische Kraft des Menschen, an die Kraft etwas neues zu erschöpfen. Natürlich ist es nicht dasselbe wie Erschaffen eines Kunstwerkes oder eines Musikstückes, weil das, was erkannt wird, schon da ist, es nicht aus Nichts geschaffen wird. Und doch ist auch das Gewinnen der Erkenntnisse aus der Erfahrung, die vorher nicht waren, ist das Gewinnen von etwas neuem, also ein schöpferischer Vorgang. Und dieser Übergang zwischen einer die Befehle ausführenden und einer lernenden Maschine ist wohl die Grenze, ab der die Maschinen intelligent werden.
Wie weit die künstliche Intelligenz reicht oder reichen kann, lässt sich noch nicht sagen. Wir haben noch keine Roboter, die malen, Romane oder Lieder schreiben oder physikalische Gesetze entdecken. Wie am Beispiel mit dem neuronalen Netz gezeigt wurde, geht es bei maschinellem Lernen um das Erkennen bestimmter Muster in der Eingabedaten. Falls so ein Muster tatsäschlich erkannt wurde, dann können anhand dessen auch neue Daten ausgewertet werden. Dem lernenden System geht es nicht um die Forschung oder die Suche nach der Wahrheit. Und hier ist es nicht mal wichtig, was Wahrheit ist, und ob es sie gibt. Wenn ein Schriftsteller schreibt, sehnt er oft aus dem tiefsten seines Herzens, seinen Lesern etwas mitzuteilen, seine Wahrheit zu verkünden. Auch ein Forscher kann von diesem Gefühl bewegt werden, selbst wenn seine Theorie sich später als falsch erweist, hat er versucht, etwas Wahres zu entdecken. Ein lernendes System hat überhaupt keinen Sinn für die Wahrheit. Es wurde programmiert, um Muster in den Daten zu erkennen und das tut es. Wenn ich weiß, wie ein System aufgebaut ist, kann ich es von vornherein mit manipulierten Daten füttern, sodass es etwas falsch lernt, und es wird sich nicht betrogen fühlen. Wobei ich zugeben muss, dass es auch einem Menschen passieren kann, dass er sich auf falsche, falsch ausgewählt Daten, stützt, und deswegen zu inkorrekten Ergebnissen gelangt.
Die Mustererkennung ist wichtig auch für das menschliche Überleben. Allerdings vermag der Mensch auch abstrakt zu denken. Es gibt zum Beispiel in der Natur keine Zahlen, es gibt nur abzählbare Gegenstände. Man muss sich von den einzelnen Gegenständen beziehungsweise ihrer endlichen Anzahl abstrahieren können, um auf die unendliche Menge von natürlichen Zahlen kommen. Diese Fähigkeit zum abstrakten Denken ist etwas, was den Menschen gegenüber den Maschinen immer noch auszeichnet.
Grenzen der Anwendung von maschinellem Lernen
Zwar ist die künstliche Intelligenz zum selbstständigen Lernen fähig, ist kein selbstständiges Lebewesen wie der Mensch, sondern nur ein Instrument unter vielen anderen.
Nehmen wir an, wir wollen quadratische Gleichungen in der Normalform lösen:
Dafür beabsichtigen wir ein Programm zu schreiben, das die 2 Parameter, und , als Eingabewerte annimmt und die Gleichung nach auflöst. Man kann diese Aufgabe durchaus mithilfe der künstlichen Intelligenz lösen. Wir entwerfen ein neuronales Netz, das zwei Neuronen in der Eingabeschicht und zwei in der Ausgabeschicht hat. Dann lösen wir einige Tausende solcher Gleichungen selbst und übergeben die Eingaben und die Lösungen dem Netz, damit es aus diesen Daten lernen kann. Dann testen wir, ob das Netz nun selbst richtige Antworten produzieren kann. Wenn es nicht der Fall sein soll, bereiten wir weitere Angaben und Lösungen vor. Irgendwann haben wir das neuronale Netz ausreichend trainiert, sodass es jetzt selbst solche Gleichungen lösen kann.
Eigentlich wissen wir aber, wie man eine quadratische Gleichung löst. Genauso gut könnten wir den folgenden Algorithmus in einem Programm implementieren:21
Berechne die Diskriminante :
Wenn ist, gibt es zwei reelle Lösungen:
Wenn ist, gibt es zwei konjugiert komplexe Lösungen:22
Der Aufwand, dieses Programm, zu schreiben ist viel geringer als die Variante mit der künstlichen Intelligenz. Was noch viel wichtiger für ein Programm, das mathematische Berechnungen durchführt, ist, ist, dass wir wissen, dass, wenn der Algorithmus korrekt implementiert ist, er richtige Ergebnisse liefert. Im Falle des neuronalen Netzes ist es nicht so. Wenn das neuronale Netz komplex genug ist, können wir nicht mehr nachvollziehen, wie eine bestimmte Berechnung durchgeführt wird, das heißt, wir können nicht überprüfen, ob der Algorithmus für alle Paare und das richtige Ergebnis liefert. Für die Anwendungsfelder des maschinellen Lernens ist eine solche Genauigkeit auch nicht unbedingt erforderlich. Wenn ein soziales Netzwerk setzt künstliche Intelligenz ein, um gezielte Werbung anzuzeigen, dann ist es durchaus vorteilhaft, wenn die Werbung den Nutzer anspricht, aber es ist immer noch zulässig, wenn die Wahl der Werbung nicht optimal ist. Es genügt, wenn die Werbung interessant genug für den Nutzer ist, oder dass ein gewisser Profit durch sie erreicht wird.
Künstliche Intelligenz ist keine universelle Lösung für alle Probleme. Sie ist sehr nützlich für die Auswertung von großen Mengen an Daten und für die Suche nach Mustern in diesen, aber ist noch nicht fähig abstrakte, e.g. mathematische Probleme zu lösen.
Fazit
Über viele Fragen lässt es heute nur spekulieren. Können die Maschinen alle Tätigkeiten ausüben, die die Menschen ausüben? Sind sie eine neue Evolutionsstufe, sodass sie die Menschen eines Tages verdrängen und überflüssig machen? Oder werden die Maschinen und Menschen weiterhin friedlich coexistieren? Einige Autoren versuchen bereits diese Fragen zu beantworten. Ich wage heute noch nicht, auf sie eine Antwort zu geben. Schließlich ist die Entwicklung der Wissenschaft und der Technik auch von einer Reihe von sozialen, politischen und wirtschaflichen Faktoren mitbestimmt.
Künstliche Intelligenz und Maschinelles Lernen ist ein junges Konzept, dem viel Aufmerksamkeit von verschiedenen Siten geschenkt wird. Die Technik und Informatik sind daran interessiert, weil es ermöglicht neue, selbst „denkende“ Programme zu schreiben; Naturwissenschaften hoffen durch künstliche auch die menschliche Intelligenz besser zu verstehen; man sieht auch Potenzial, den Menschen noch mehr vom Last der Arbeit zu befreien, aber man warnt auch vor den Gefahren der Verselbständigung der Computertechnik oder deren Missbrauch. Naturwissenschaftliche Forschung hatte schon fatale Folgen, sie ermöglichte zum Beispiel eines Tages die Erschaffung der Atomwaffen, was vielen unschuldigen Menschen ihr Leben kostete. Doch sie hat auch einen soliden Beitrag zur modernen Medizin und Technik geleistet, auf die wir uns jeden Tag verlassen. Um die künstliche Intelligenz scheint es ähnlich zu stehen: Es ist ein kontroverses Thema.
R. Kurzweil, Menschheit 2.0: Die Singularität naht, Berlin 2014, 7ff.↩︎
D. Danks, Learning, in: K. Frankish/W.M. Ramsey (Hgg.), The Cambridge Handbook of Artificial Intelligence, Cambridge 2014, 151–167, 154.↩︎
I.N. da Silva u. a., Artificial Neural Networks: A Practical Course, Switzerland 2017, 27.↩︎
Danks, Learning, 154.↩︎
E. Kandel, Auf der Suche nach dem Gedächtnis: Die Entstehung einer neuen Wissenschaft des Geistes, München 2006, 75.↩︎
Vgl. ebd. 79.↩︎
Ebd. 81.↩︎
Ebd.↩︎
Vgl. ebd. 220.↩︎
Vgl. Silva u. a., Artificial Neural Networks, 22.↩︎
Ebd. 15.↩︎
A.M. Turing, Computing Machinery and Intelligence, in: Mind 59 (1950), 433–460, 433f.↩︎
Ebd.↩︎
Ebd. 434.↩︎
S. Kierkegaard, Die Krankheit zum Tode: Eine christlich-psychologische Darlegung zur Erbauung und Erweckung, übers. von G. Perlet, Copenhagen 2015, 11.↩︎
Y. Förster, Effects of the Neuro-Turn: The Neural Network as a Paradigm for Human Self-Understanding, in: J. Leefmann/E. Hildt (Hgg.), Cambridge 2017, 164.↩︎
Kierkegaard, Die Krankheit zum Tode, 11.↩︎
Förster, Effects of the Neuro-Turn, 163.↩︎
D. Nauer, Seelsorge: Sorge um die Seele, Stuttgart 32014, 35.↩︎
Förster, Effects of the Neuro-Turn, 172.↩︎
Vgl. L. Papula, Mathematik für Ingenieure und Naturwissenschaftler: Ein Lehr- und Arbeitsbuch für das Grundstudium, Bd. 1, Wiesbaden 122009, 10f.↩︎
Vgl. ebd. 676.↩︎